HDFS概念
HDFS定义
HDFS是Hadoop的一个分布式文件系统,全称叫Hadoop Distributed File System。
HDFS特点
高容错性
HDFS 可以稳定运行在商用硬件集群上,有冗余副本,心跳机制,安全模式等功能
支持元数据快照,将失效的集群回滚到之前一个正常的时间点上。
大数据集存储
一个磁盘无法放下的 GB 或 TB 的文件,HDFS将它分成小块(block)存储。
一致性模型(write-once-read-many)
HDFS 通常是一次写入,多次读取,不支持随机写操作,可以在文件末尾追加。
适合于分布式计算
一般的计算需要将数据输入到程序中,网络传输大文件比较慢。
HDFS则是提供接口将计算先放到每块数据中执行,最后再将结果合并。
与Hadoop关系
Hadoop是一个分布式系统基础架构,其中核心组件有HDFS,MapReduce,YARN。
HDFS架构
架构图
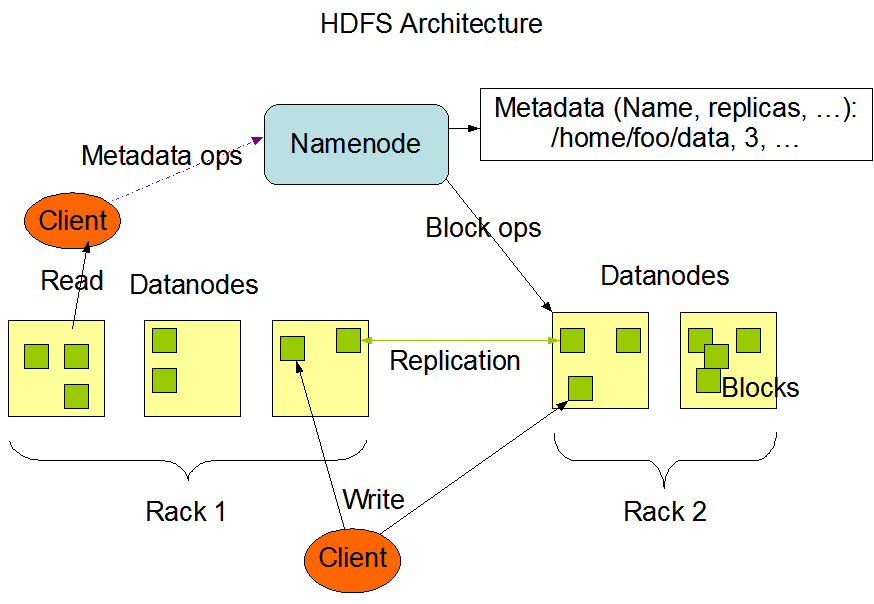
主从结构
由一个Namenode和一定数目的Datanodes组成。
Namenode是一个中心服务,
- 负责管理文件系统的Namespace;
- 数据块到具体Datanode节点的映射和数据块到文件的映射;
- 负责执行文件系统的Namespace操作,比如打开、关闭、重命名文件或目录;
集群中的Datanode一般是一个节点一个
- 负责管理它所在节点上数据的存储;
- 负责处理文件系统客户端的读写请求;
- 在Namenode调度下进行数据块的创建、删除和复制;
- 周期性的上报心跳信号和块状态报告到Namenode;
HDFS数据存储
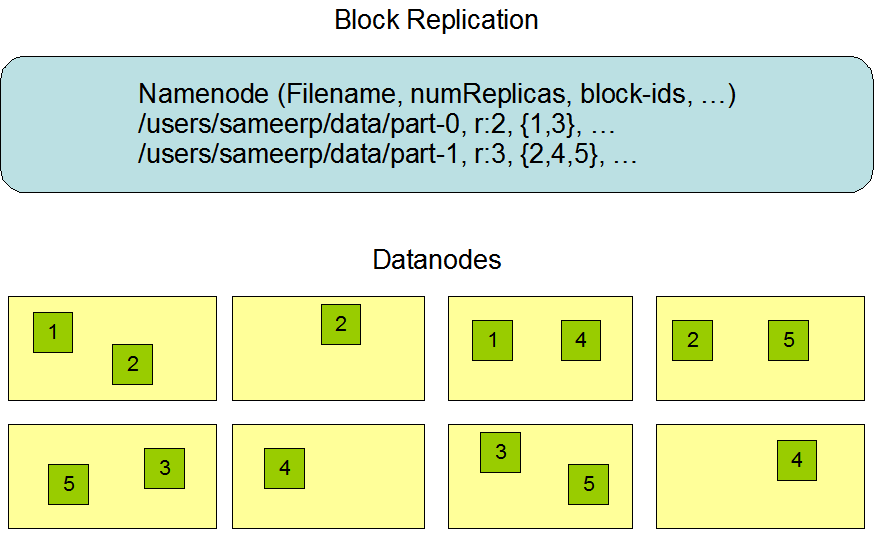
分块存储
一个大文件存储到HDFS上,会被分成多个Block。目前HDFS分块默认为128M,支持修改。
如果文件大小没有到达块的最小空间,该文件只会占据自己本身空间大小。
备份机制
HDFS默认备份3份,存储在不同的Datanode节点中。
每个文件的数据块大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
机架感知
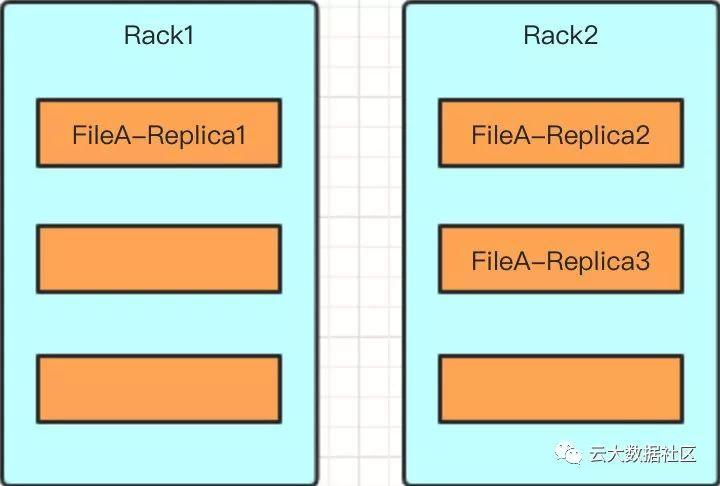
为了防止当整个机架失效时数据的丢失,Datanode一般会分布在不同的机架上。
另外可以在读取数据的时候计算最近的副本的距离,尽量使用同一个机架上的Block。
首先通过管理员手动配置机器与机架的关系,一般是维护一个map,将脚本文件配置在配置文件中。
FsImage 和 EditLog
- EditLog:保存元数据更改记录,一个文件只记录一段时间的信息。
- FsImage:保存文件系统目录树以及文件和 block 的对应关系,理解为元数据镜像文件,某个时刻整个 HDFS 系统文件信息的快照;
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大
- SecondaryNameNode:定期合并NameNode的edit logs到fsimage文件中
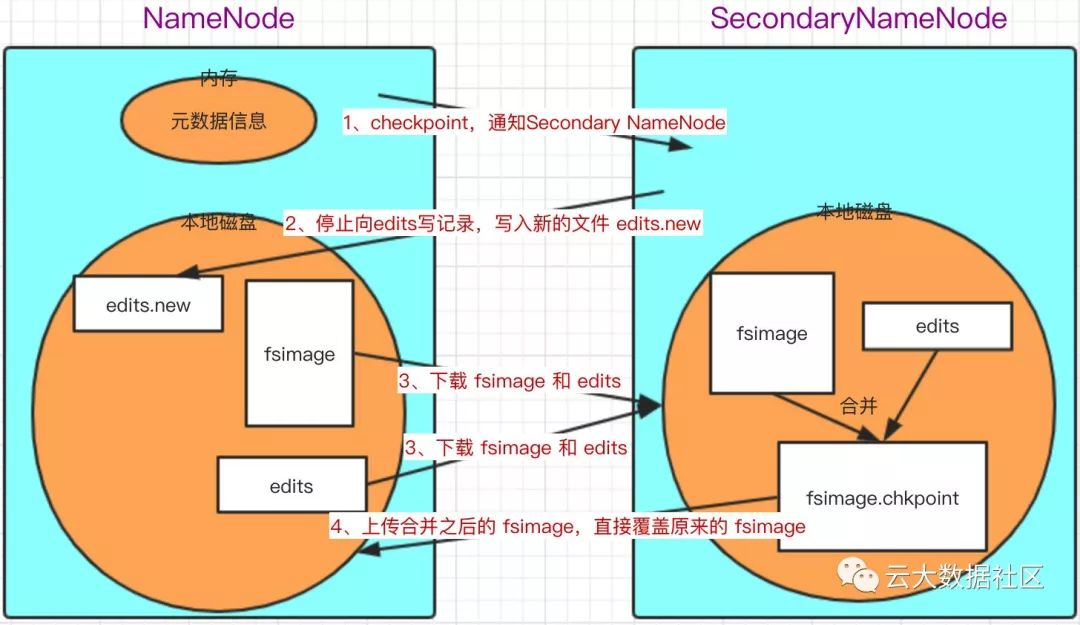
- 触发检查点(定期/定多少事务记录)
- 触发 checkpoint,NameNode 停止向 edits 中写新的记录,另外生成一个 edits.new 文件,将新的事务记录在此文件中
- SecondaryNameNode 通过 HTTP 请求,从 NameNode 下载 fsimage 和 edits 文件,合并生成 fsimage.chkpoint 文件;
- SecondaryNameNode 再将新生成的 fsimage.chkpoint 上传到 NameNode 并重命名为 fsimage,直接覆盖旧的 fsimage,实际上中间的过程还有一些 MD5 完整性校验,检查文件上传下载后是否完整;
- 将 edits.new 文件重命名为 edits 文件,旧的 edits 文件已经合并到 fsimage;
HDFS文件读写
运行在HDFS上的应用和普通的应用不同,需要流式访问它们的数据集。HDFS的设计中更多的考虑到了数据批处理,而不是用户交互处理。比之数据访问的低延迟问题,更关键的在于数据访问的高吞吐量。POSIX标准设置的很多硬性约束对HDFS应用系统不是必需的。为了提高数据的吞吐量,在一些关键方面对POSIX的语义做了一些修改。
HDFS中的block、packet、chunk
block
文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
读数据过程
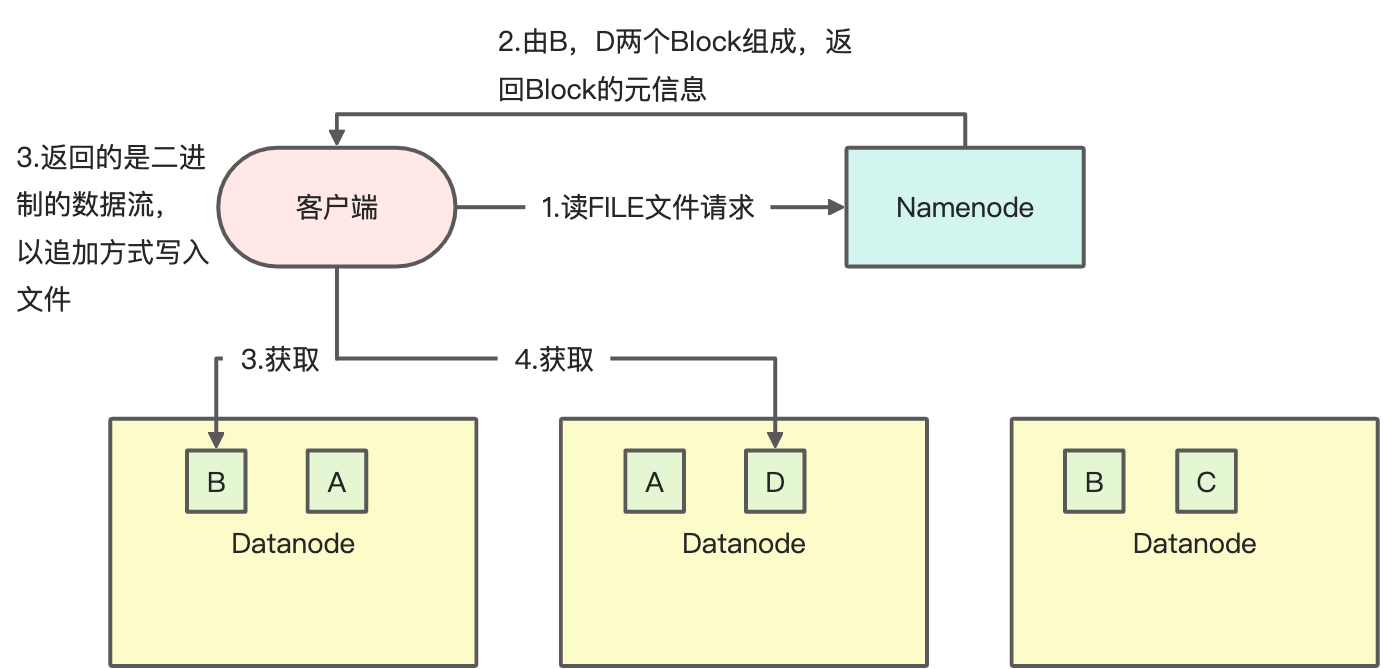
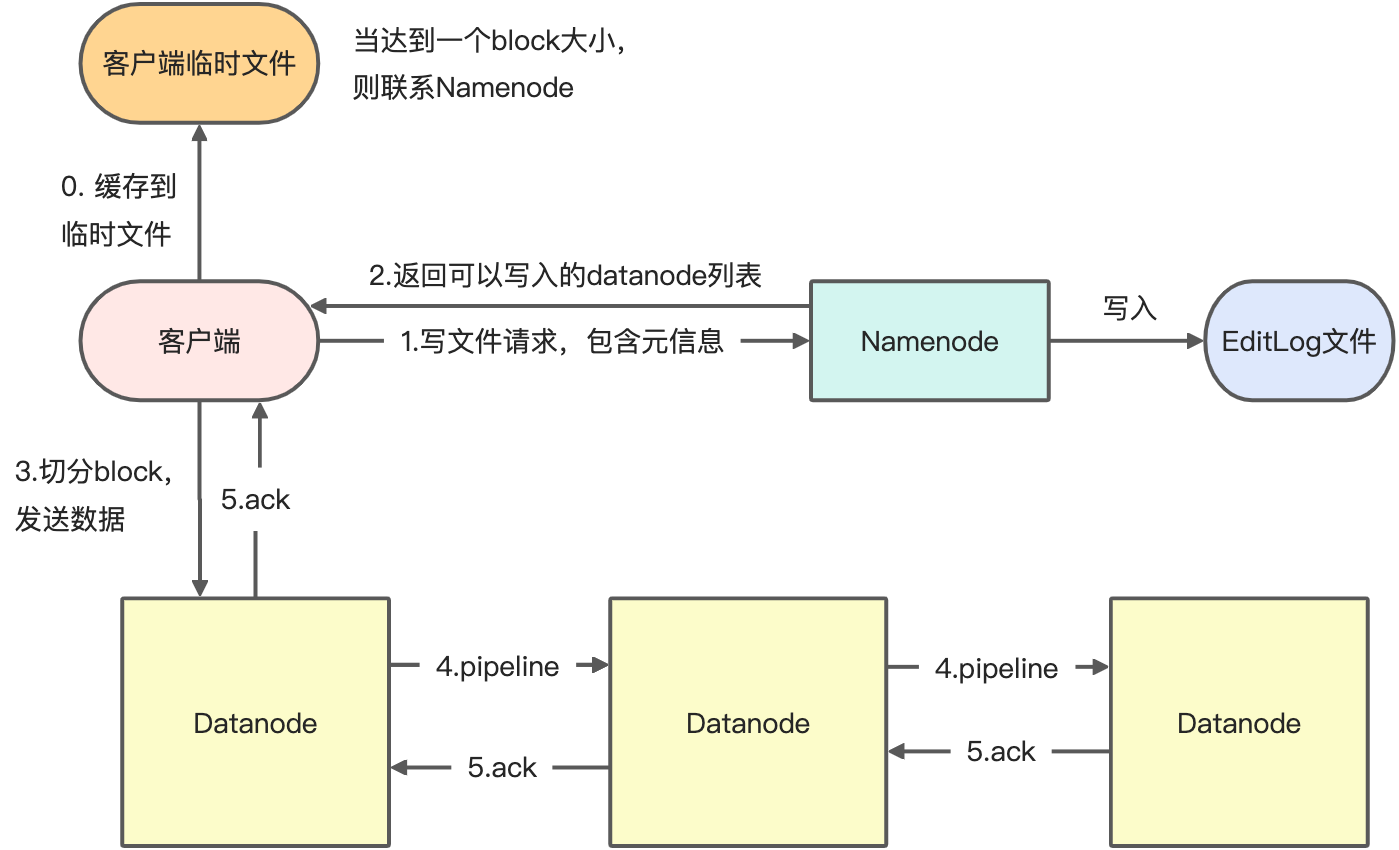
写数据过程
参考资料
Hadoop官方文档V3.3版本
大数据之 HDFS 图文详解
分布式文件系统架构对比
分布式存储glusterfs
机架感知概念及配置实现
TFS的原理与使用
Hadoop数据完整性与CheckSum校验原理
HDFS读写流程
CRUSH算法的原理与实现
Hadoop个人分享
附件
文件系统简介
文件系统是计算机中一个非常重要的组件,为存储设备提供一致的访问和管理方式。
可移植操作系统接口(英语:Portable Operating System Interface,缩写为POSIX)是IEEE为要在各种UNIX操作系统上运行软件,而定义API的一系列互相关联的标准的总称。
通用属性
数据是以文件的形式存在,提供 Open、Read、Write、Seek、Close 等API 进行访问;
文件以树形目录进行组织,提供原子的重命名(Rename)操作改变文件或者目录的位置
单机文件系统
windows:FAT/FAT32/NTFS,linux:EXT2/EXT3/EXT4/XFS/BtrFS,mac:APFS
单机文件系统挑战
- 共享:无法同时为分布在多个机器中的应用提供访问,于是有了 NFS 协议,可以将单机文件系统通过网络的方式同时提供给多个机器访问。
- 容量:无法提供足够空间来存储数据,数据只好分散在多个隔离的单机文件系统里。
- 性能:无法满足某些应用需要非常高的读写性能要求,应用只好做逻辑拆分同时读写多个文件系统。
- 可靠性:受限于单个机器的可靠性,机器故障可能导致数据丢失。
- 可用性:受限于单个操作系统的可用性,故障或者重启等运维操作会导致不可用。
开源分布式架构对比
| 分布式文件系统 | 开发语言 | 使用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| HDFS | JAVA | 大文件存储,大数据分析 | 1. 经典 1. 大数据场景有优势 1. 用户数量大 1. 资料丰富 1. 高吞吐 |
1. 不通用,并不提供完整的POSIX语义 1. 小文件性能较差 1. 只支持追加写 1. 不能低延迟 |
| GlusterFS | C | 大文件存储场景 | 1. 老牌分布式文件系统 1. 应用众多 1. 云存储和流媒体 1. 没有元数据服务器的设计,无单点故障 |
1. 扩容、缩容时影响的服务器较多 1. 小文件性能较差 |
| CephFS | C++ | 单机群大中小文件 | 1. crush算法比较有特点 1. ceph架构支持块存储,对象存储,文件存储 |
1. 不够成熟稳定,问题较多 1. 读写效率不高 |
| MooseFS | C | 单机群大中小文件 | 1. 通过fuse支持了标准的posix,实现通用的文件系统 |
1. 社区不活跃 1. Master Server本身的性能瓶颈 |
| TFS | C++ | 主要设计用于小于1MB的小文件 | 1. 解决分布式文件系统小文件的问题 |
1. 文档不全 1. 使用较为困难 |
为什么要设置Block为128M
- 如果块设置过大
- 从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
- mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢。
- 如果块设置过小
- 存放大量小文件会占用NameNode中大量内存来存储元数据,而NameNode的内存是有限的,不可取;
- 文件块过小,寻址时间增大,导致程序一直在找block的开始位置。
- HDFS中平均寻址时间大概为10ms;
- 经过前人的大量测试发现,寻址时间为传输时间的1%时,为最佳状态;
所以最佳传输时间为10ms/0.01=1000ms=1s- 目前磁盘的传输速率普遍为100MB/s;
网络拓扑机器之间的距离
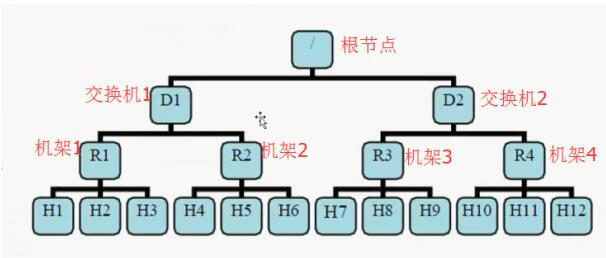
D1,R1 都是交换机,最底层是 datanode。则 H1 的
rackid=/D1/R1/H1,H1 的 parent 是 R1,R1 的是 D1。这些 rackid
信息可以通过 topology.script.file.name 配置。有了这些 rackid 信息
就可以计算出任意两台 datanode 之间的距离。
1.distance(/D1/R1/H1,/D1/R1/H1)=0 相同的 datanode
2.distance(/D1/R1/H1,/D1/R1/H2)=2 同一 rack 下的不同 datanode
3.distance(/D1/R1/H1,/D1/R1/H4)=4 同一 IDC(互联网数据中心
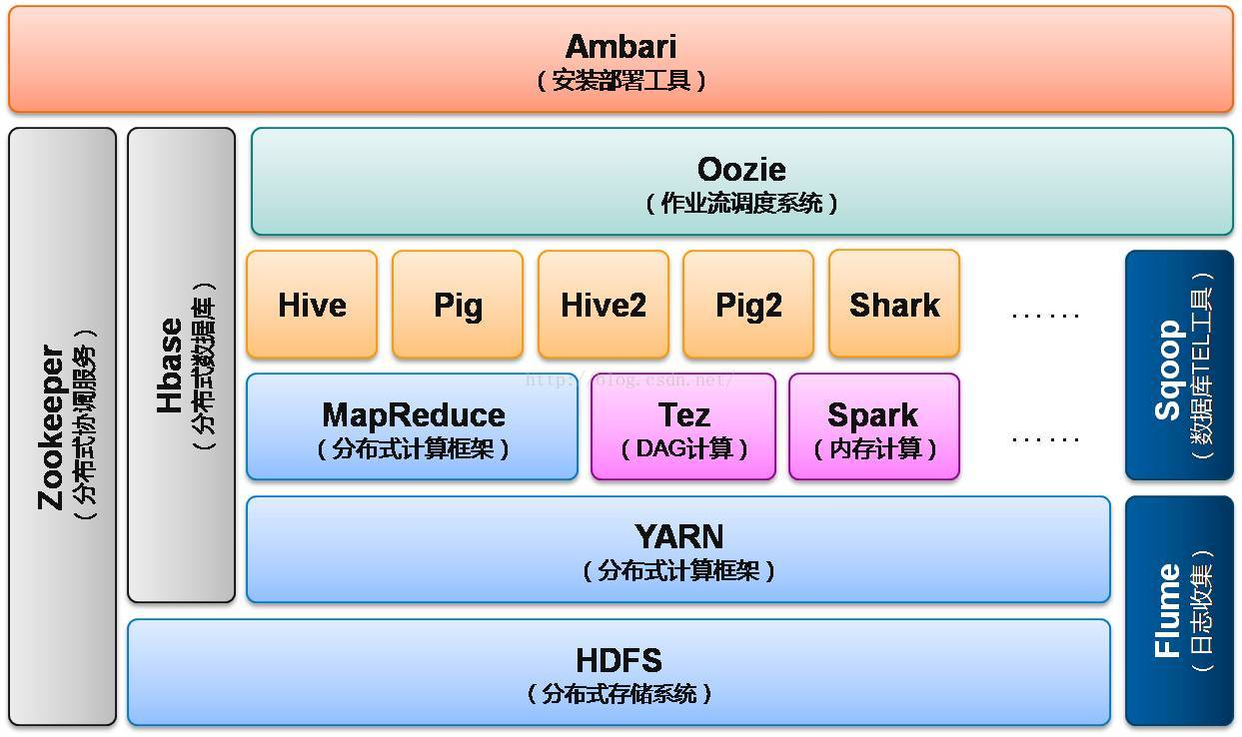
hadoop2.x架构图
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏一下