前言
这边来看一个sql中统计某列最新不同值的方法。
直接说上面这个比较难以理解,具体场景举例如:
- 用户访问记录表,统计最近访问的不同的n个用户
- 操作记录表,统计最近不同的n个操作
看似简单实际上只通过简单的一层sql无法实现。
这边用实操演示,三种可用的实现方式。
实操
这边来实际操作下,为了方便这边用MYSQL为例
准备数据
这个表表示用户资源访问记录表,其中有主键id,用户id,资源id,访问时间。
用户每访问一次资源则记录加一条。
1 | CREATE TABLE IF NOT EXISTS `user_resource_history` ( |
导入一些数据,
1 | INSERT INTO user_resource_history (id, user_id, resource_id, date_created) VALUES (1, 1, 1, '2020-12-24 02:03:17'); |
大致数据为
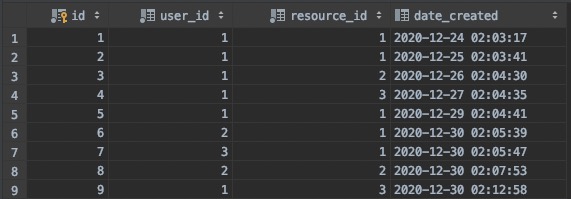
目标
统计用户1的最近访问的3个不同资源和访问时间
分析思路
首先考虑select的where过滤user_id=1,
然后因为是3个不同资源,得按资源分组,得到类似于下面的kv结构
1 | { |
然后从时间数组中挑选出最近的时间。就得到如下表:
| 资源id | 最近访问时间 |
|---|---|
| 1 | 2020-12-31 02:12:58 |
最后再按最近访问时间倒排序即可得到 :用户1的最近访问的3个不同资源和访问时间
MYSQL实现
再具体实现过程中,因为不存在数组这个,所以略有不同。
第一种实现
第一种通过rank()函数实现,这个得在Mysql8.0才有这个函数
它的语法是如下,这个意思就是按这个分区字段分类,按排序字段排序,产生一个排名字段rk
1 | rank() over ( |
整体实现如下
1 | -- 外层筛选排名为第一名的数据,表示不同资源最近一条 |
第二种实现
因为在mysql5.x中都不能用rank函数,所有这边有另一种奇妙的实现,
整体还是实现上面的排名,通过case when的方式。
sql如下:
首先将原表按照resource_id,date_created排序,这样就可以将同样的resource_id归到一起,且按照时间倒序。
然后增加一列排名,排名的实现:
先定义两个变量,这边是curRank,preRank
curRank这边表示的是上一个资源id,
preRank表示的是排名
当从上往下遍历时,当preBank = resource_id时,curRank赋值为1,(表示每个新资源排名从1开始)
当preRank != resource_id时,curRank += 1, (同一个资源内,每次排名自增)
产生排名后外层筛选排名为1的,再重新按时间进行倒排序。
1 | select resource_id, date_created from ( |
第三种实现
这个实现需要建的时候按有自增id主键的建表,
且时间是按数据库自增的,这样id的最大值表示的就是最新时间。
首先按照资源id聚合,查看的是max(id),因为最大id行就表示该资源最近时间行。得到一批id
然后在用in这批id则可以得到每个资源最近时间的表,在按时间倒排序一下,
就可以得到结果
1 | select resource_id, date_created |
时间测试估计
由于这边测试数据比较少,
大致结果为第一种40ms,第二种70ms,第三种40ms
三种中,第二种总体比较慢,因为多层一次子查询。
其他想法
当然在真实前提场景可变的情况下,可以直接另建一张表,表示用户最近访问不同资源表。
每次访问资源时,除了更新记录表,也可以更新用户最近访问资源表。
或者定时将记录表更新至最近访问资源表。
最后
sql还是有学习空间。
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
赞赏一下