逻辑执行
首先看下之前的总体处理流程
1 2 3 4 5 Hive SQL - (Parser) -> AST - (Semantic Analyze) -> QB - (Logical Plan) -> Operator Tree - (Physical Plan) -> Task Tree - (Physical Optim) -> Task Tree 主要有三大块,SQL解析,逻辑执行计划,物理执行计划
hive在sql解析后生成了AST树,然后的处理是通过SemanticAnalyzer将AST变成逻辑执行计划OperatorTree。
首先看一个命令explain {SQL}
可以打印出执行sql对应的OperatorTree,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 hive> explain select count(1) from test_user group by `name`; OK STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 depends on stages: Stage-1 STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: test_user Statistics: Num rows: 2 Data size: 16 Basic stats: COMPLETE Column stats: NONE Select Operator expressions: name (type: string) outputColumnNames: name Statistics: Num rows: 2 Data size: 16 Basic stats: COMPLETE Column stats: NONE Group By Operator aggregations: count(1) keys: name (type: string) mode: hash outputColumnNames: _col0, _col1 Statistics: Num rows: 2 Data size: 16 Basic stats: COMPLETE Column stats: NONE Reduce Output Operator key expressions: _col0 (type: string) sort order: + Map-reduce partition columns: _col0 (type: string) Statistics: Num rows: 2 Data size: 16 Basic stats: COMPLETE Column stats: NONE value expressions: _col1 (type: bigint) Reduce Operator Tree: Group By Operator aggregations: count(VALUE._col0) keys: KEY._col0 (type: string) mode: mergepartial outputColumnNames: _col0, _col1 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE Select Operator expressions: _col1 (type: bigint) outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE File Output Operator compressed: false Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: NONE table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: ListSink Time taken: 1.999 seconds, Fetched: 52 row(s)
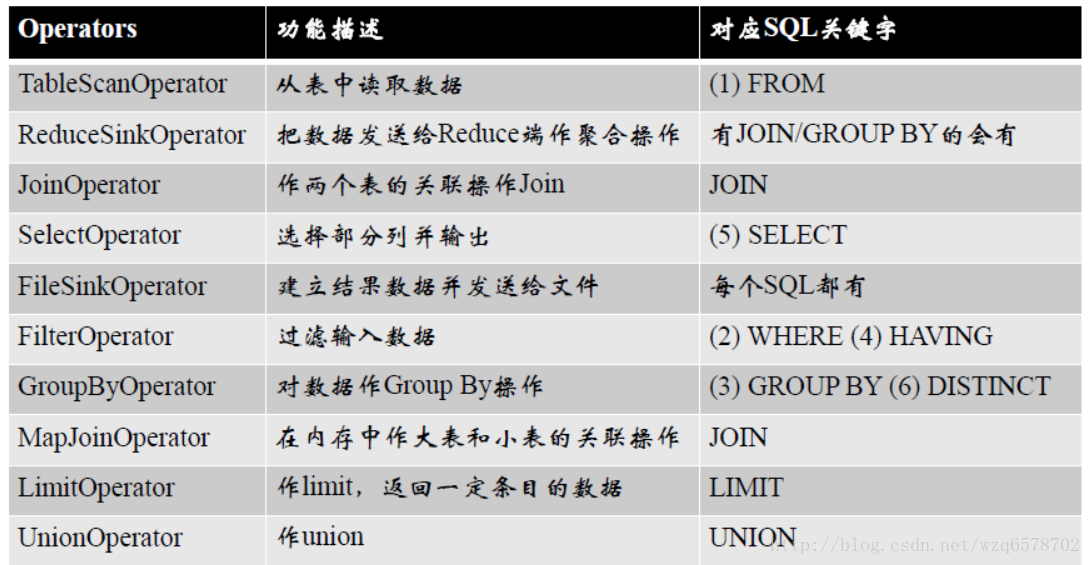
对应下下面这张Operator的列表,可以稍微了解到对SQL对应的每个operator
继续跟踪大法,从Driver的compile开始
定位到下面这行,进入
sem.analyze(tree, ctx);
1 2 3 4 public void analyze (ASTNode ast, Context ctx) throws SemanticException ... analyzeInternal(ast); }
继续进入analyzeInternal方法,这时已经定位到SemanticAnalyzer类了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void analyzeInternal (ASTNode ast, PlannerContext plannerCtx) throws SemanticException LOG.info("Starting Semantic Analysis" ); if (!genResolvedParseTree(ast, plannerCtx)) { return ; } Operator sinkOp = genOPTree(ast, plannerCtx); ... Optimizer optm = new Optimizer(); optm.setPctx(pCtx); optm.initialize(conf); pCtx = optm.optimize(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 boolean genResolvedParseTree (ASTNode ast, PlannerContext plannerCtx) throws SemanticException ... Phase1Ctx ctx_1 = initPhase1Ctx(); preProcessForInsert(child, qb); if (!doPhase1(child, qb, ctx_1, plannerCtx)) { return false ; } ... getMetaData(qb); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public boolean doPhase1 (ASTNode ast, QB qb, Phase1Ctx ctx_1, PlannerContext plannerCtx) throws SemanticException { ... switch (ast.getToken().getType()) { case HiveParser.TOK_SELECTDI: ... case HiveParser.TOK_SELECT: ... case HiveParser.TOK_WHERE: ... case HiveParser.TOK_INSERT_INTO: ... ... } }
继续跟上面的genOPTree,跳转到genPlan
genPlan是一次如下的深度优先遍历生成树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 private Operator genPlan (QB parent, QBExpr qbexpr) throws SemanticException if (qbexpr.getOpcode() == QBExpr.Opcode.NULLOP) { boolean skipAmbiguityCheck = viewSelect == null && parent.isTopLevelSelectStarQuery(); return genPlan(qbexpr.getQB(), skipAmbiguityCheck); } if (qbexpr.getOpcode() == QBExpr.Opcode.UNION) { Operator qbexpr1Ops = genPlan(parent, qbexpr.getQBExpr1()); Operator qbexpr2Ops = genPlan(parent, qbexpr.getQBExpr2()); return genUnionPlan(qbexpr.getAlias(), qbexpr.getQBExpr1().getAlias(), qbexpr1Ops, qbexpr.getQBExpr2().getAlias(), qbexpr2Ops); } } public Operator genPlan (QB qb) throws SemanticException return genPlan(qb, false ); } public Operator genPlan (QB qb, boolean skipAmbiguityCheck) throws SemanticException { for (String alias : qb.getSubqAliases()) { QBExpr qbexpr = qb.getSubqForAlias(alias); aliasToOpInfo.put(alias, genPlan(qb, qbexpr)); } ... }
优化器
上面也已经涉及到优化器optimizer,
optimizer的主要功能
(1)将多 multiple join 合并为一个 multi-way join;
追踪Optimizer.initialize
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public void initialize (HiveConf hiveConf) transformations = new ArrayList<Transform>(); transformations.add(new HiveOpConverterPostProc()); transformations.add(new Generator()); ... } public ParseContext optimize () throws SemanticException for (Transform t : transformations) { pctx = t.transform(pctx); } return pctx; }
未完待续,join operator
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏