起意是在看一些招聘算法机器学习面经的时候有看到好几次让直接写一个kmeans。之前用sklearn试过这个聚类算法,这次也来手写实现一下。
import random
import matplotlib.pyplot as plt
#生成点
def make_points():
points = []
for i in range(100):
points.append([random.random()*10,random.random()*10])
points.append([random.random()*-10,random.random()*-10])
points.append([random.random()*10,random.random()*-10])
points.append([random.random()*-10,random.random()*10])
return points
#计算距离,这里用欧式距离,也可以换其他距离
def calc_distance(p1,p2):
return ((p1[0]-p2[0])**2+(p1[1]-p2[1])**2)**0.5
#转置
def listT(arr):
return list(map(list, zip(*arr)))
#主算法部分,递归实现
def kmeans(points,cate_num,cate_mid=None,n=0,nmax=100):
#初始化中心点
if cate_mid == None:
cate_mid = [points[i] for i in range(cate_num)]
category = {}
#初始化类别
for i in range(cate_num):
category[i] = []
#计算每个点与中心点的距离,去最小值,划入那个中心点的类中
for point in points:
dis = [calc_distance(point,i) for i in cate_mid]
category[dis.index(min(dis))].append(point)
#转置得到每类点的x和y,并求平均。
ch_cate_mid = []
for i in category:
tmpx,tmpy = listT(category[i])
count = len(tmpx)
ch_cate_mid.append([sum(tmpx)/count,sum(tmpy)/count])
#n为次数,次数达到后返回类别与点
if n >= nmax:
return category
else:
return kmeans(points,cate_num,ch_cate_mid,n+1)
if __name__ == "__main__":
#运行kmeans
points = make_points()
cate_num = 4
category = kmeans(points,cate_num)
#画图部分
color = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'w']
for i in category:
xy = listT(category[i])
plt.plot(xy[0],xy[1],color[i]+".")
#plt.show()
plt.savefig("kmeans.png")
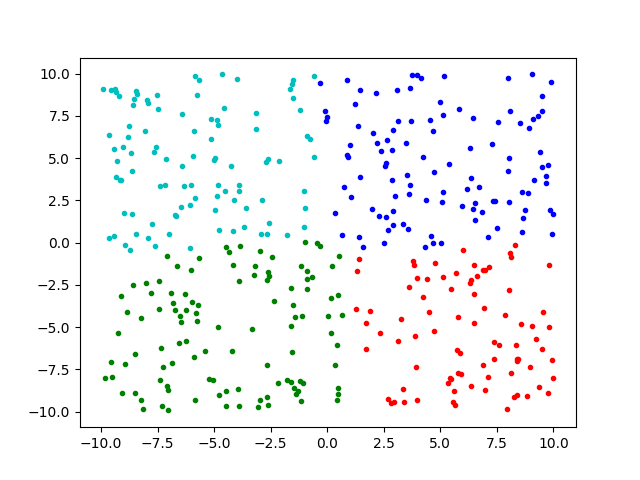
效果展示:
版权声明:本文为原创文章,转载请注明出处和作者,不得用于商业用途,请遵守
CC BY-NC-SA 4.0协议。
赏
 支付宝打赏
支付宝打赏
 微信打赏
微信打赏
支付宝打赏
微信打赏
赞赏一下